Data Pipeline for Processing CSV Files Using S3, Lambda, Glue, and QuickSight
2.1 Project Overview and Business Context
This project demonstrates how to build an automated serverless data pipeline on AWS for processing CSV files and generating business insights through dashboards. The solution uses services such as Amazon S3, AWS Lambda, AWS Glue, and Amazon QuickSight to automate the ingestion, transformation, and visualization of data.
The pipeline begins when CSV files are uploaded to an Amazon S3 bucket, which acts as the storage layer for raw data. An S3 event trigger activates an AWS Lambda function, initiating the processing workflow. The Lambda function performs initial preprocessing tasks and prepares the data for transformation.
Next, AWS Glue is used to perform ETL (Extract, Transform, Load) operations, cleaning and transforming the dataset into a structured format suitable for analysis. Glue Crawlers catalog the processed data and store metadata in the Glue Data Catalog, enabling downstream services to query the data efficiently.
Finally, the transformed data is visualized using Amazon QuickSight, where interactive dashboards provide insights into the processed dataset. This serverless architecture enables automated data processing without requiring infrastructure management.
Serverless data pipelines like this allow organizations to automatically process incoming datasets and generate analytics-ready insights in near real time.
Business Context
Organizations frequently collect data from various sources such as application logs, transaction systems, or external partners, often in CSV format. Manually processing and analyzing this data can be time-consuming and prone to human error.
A serverless data pipeline automates the ingestion, transformation, and visualization of data, enabling businesses to process large datasets efficiently and generate actionable insights.
This architecture helps organizations:
Automate data ingestion and processing workflows
Transform raw datasets into analytics-ready formats
Reduce manual data preparation and reporting efforts
Generate real-time insights through dashboards and visualizations
Solutions like this are commonly used in:
Business intelligence and analytics platforms
Sales and marketing data analysis
Log and event data processing
Operational reporting systems
By leveraging AWS serverless services, organizations can build scalable, event-driven data pipelines that automatically process data as it arrives, reducing operational overhead while enabling faster decision-making.
Architecture Components
Data Ingestion Layer: Amazon S3 stores raw CSV files uploaded to the pipeline.
Processing Layer: AWS Lambda is triggered by S3 events and initiates preprocessing tasks.
ETL Layer: AWS Glue performs data transformation and schema discovery using Glue Crawlers and ETL jobs.
Metadata Layer: The AWS Glue Data Catalog stores metadata about datasets, enabling efficient querying.
Analytics & Visualization: Amazon QuickSight connects to the processed dataset to create dashboards and visual reports.
Services Used
Amazon S3: Stores raw and processed CSV data used in the pipeline. (Storage)
AWS Lambda: Automates event-driven preprocessing when new data is uploaded. (Compute)
AWS Glue: Performs ETL transformations and manages the Data Catalog for structured datasets. (Data Integration)
Amazon QuickSight: Provides interactive dashboards and visualizations for analyzing processed data. (Analytics)
IAM Roles and Policies: Controls permissions between services to ensure secure interactions. (Security)
1.2 Setup and Configuration
Steps to be Performed
Create S3 Buckets
Configure IAM Roles and Policies
Setup Amazon QuickSight
#1 Create S3 Bucket
Amazon S3 will be the backbone of our pipeline, acting as storage for raw, processed and final data. Here we will be creating three S3 buckets for storing— Raw, processed and final data respectively.
Log in to AWS Console and navigate to the S3 service.
Click on “Create bucket”.
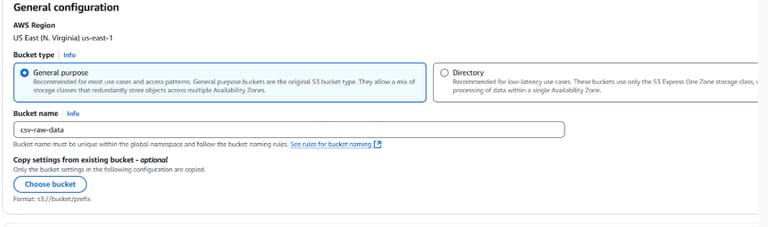
Fill out the following details:
- Bucket Name: Use descriptive names like csv-raw-data for raw data , csv-processed-data for processed data and csv-final-data for final data.
- Region: Choose the same region for all resources in this project (e.g., us-east-1).
Leave the rest of the options at default and click Create bucket.
Repeat this process to create a other two buckets for processed data and final data.
In the end, you should be having 3 buckets for raw, processed and final data.
#2 Configure IAM Roles and Policies
IAM (Identity and Access Management) ensures our services can securely communicate and operate. We will ensure proper permissions are given to AWS Lambda and AWS Glue. For that—
Create an IAM Role for Lambda:
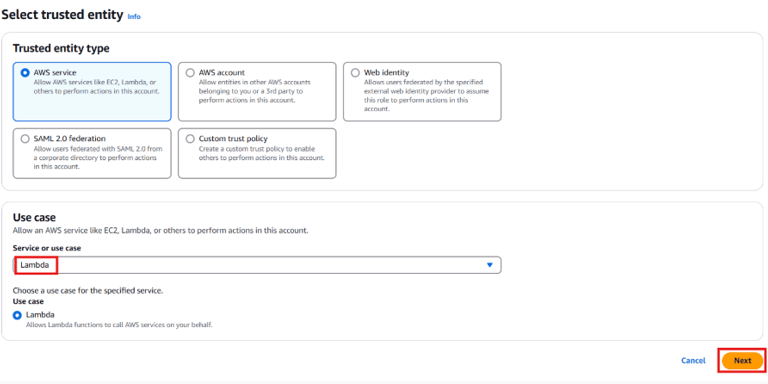
Go to the IAM Console → Roles → Create role.
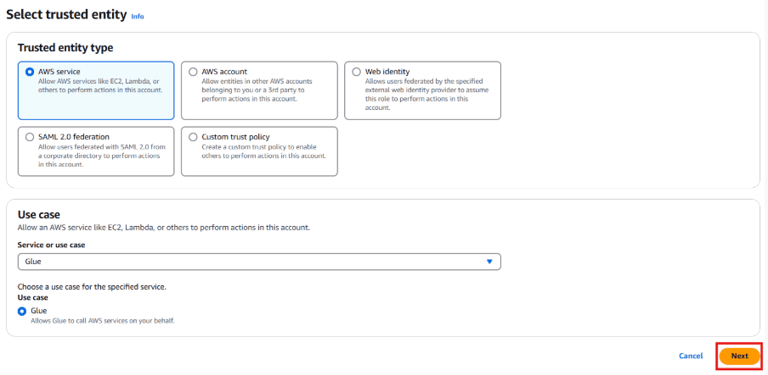
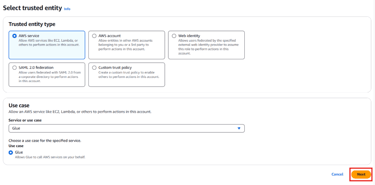
Select AWS Service as the trusted entity and choose Lambda.
Click Next and attach the following policies:
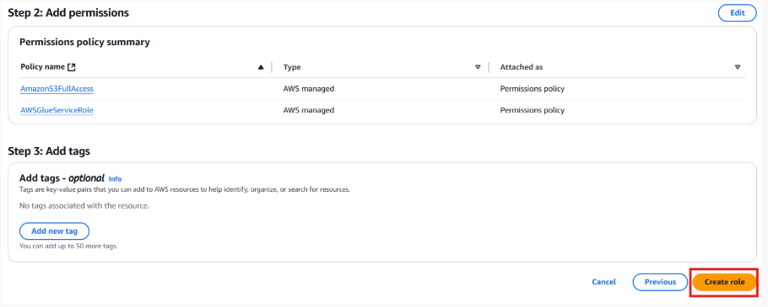
- AmazonS3FullAccess (to read/write S3 buckets).
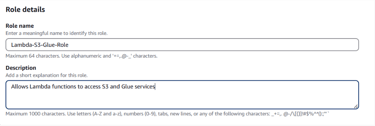
- AWSGlueServiceRoll (for Glue operations).Name the role Lambda-S3-Glue-Role and click Create Role.
Create an IAM Role for Glue:
Go to Roles → Create role.
Select AWS Service and choose Glue.
Security Note: Attach only the permissions necessary for your pipeline to reduce security risks.
#3 Set Up Amazon QuickSight
Amazon QuickSight helps you visualize your processed data. Let’s setup your QuickSight account:
Open QuickSight:
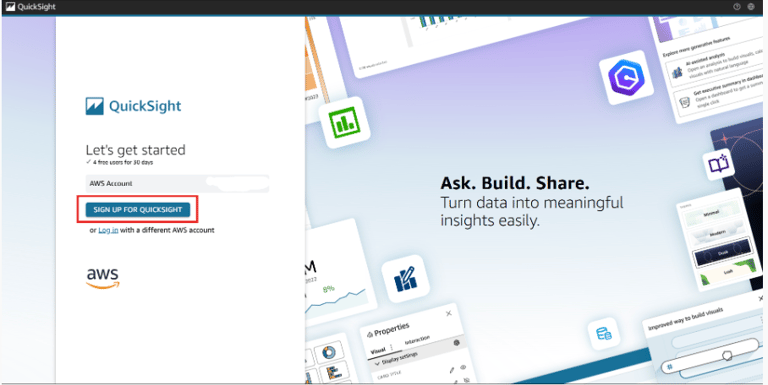
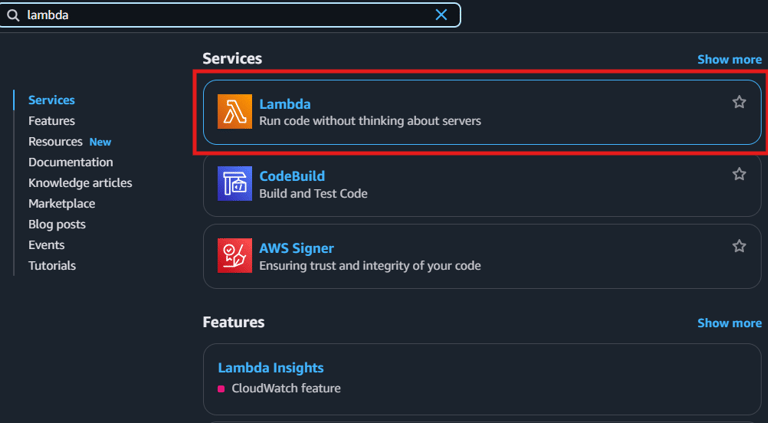
In the AWS Console, search for QuickSight and open the service.
If you don’t have an account yet, click Sign up for QuickSight.
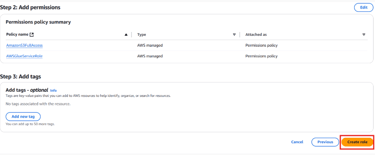
Attach these policies:
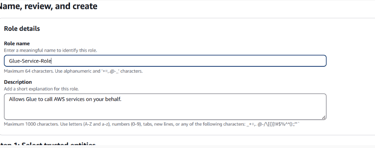
- AWSGlueServiceRole
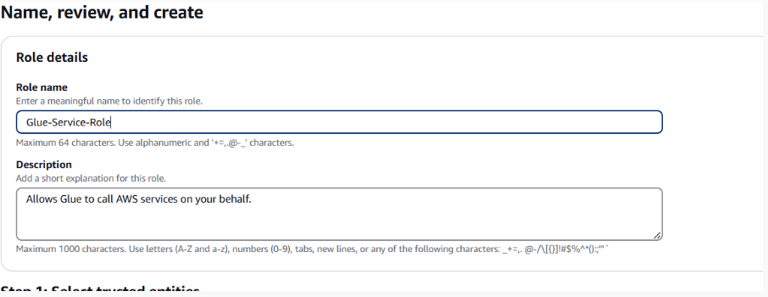
- AmazonS3FullAccessName the role Glue-Service-Role and click Create Role.
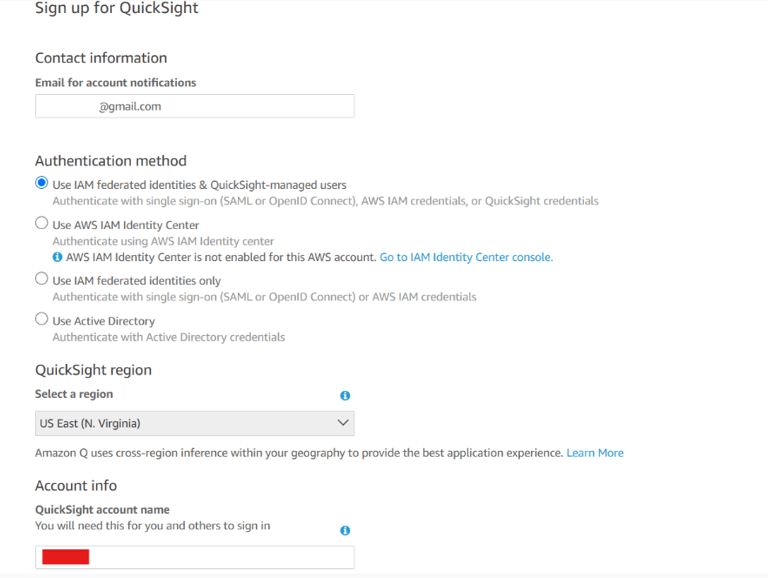
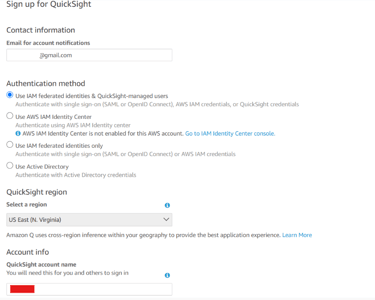
Add your email. For the Authentication Method, check Use IAM federated identities & QuickSight-managed users . Choose the US-East region (Same region as your buckets).Add a QuickSight Account Name.
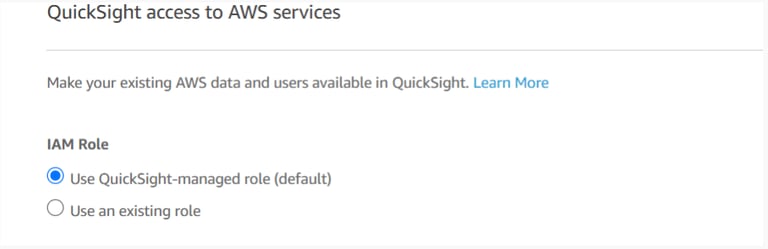
For the IAM role, check the Use QuickSight-managed role (default).
Configure QuickSight Settings:
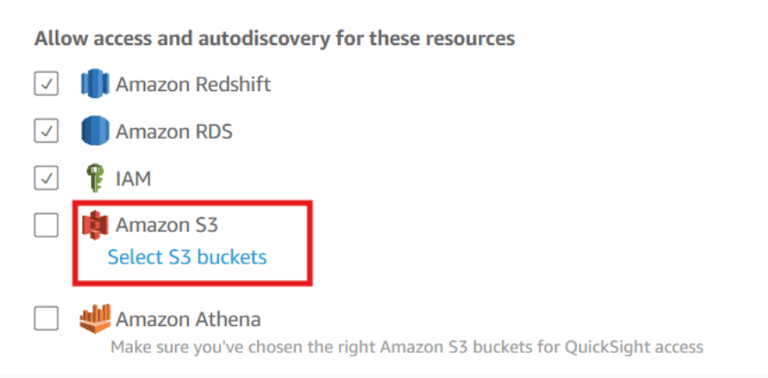
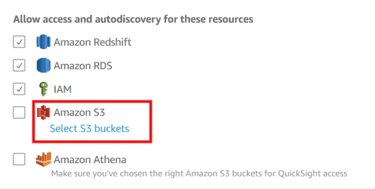
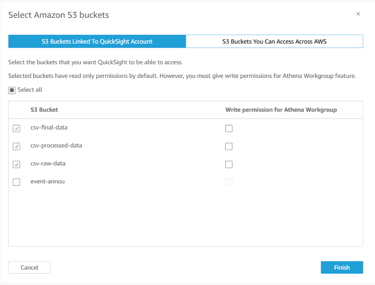
In the Allow Access, Click on Select S3 Buckets.
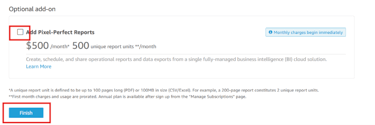
Select the previously created three S3 buckets. Click on Finish.
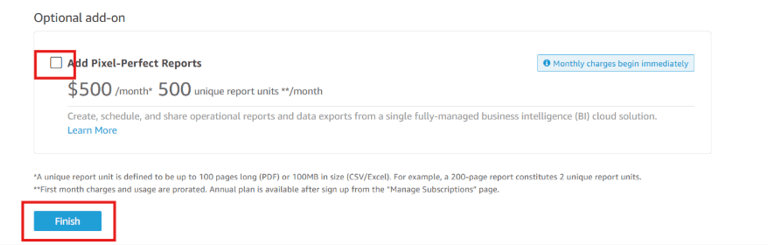
Uncheck the option- Add Pixel Perfect Reports and click on Finish.
Now QuickSight is ready to access and visualize data from S3!
Final Check
You should now have:
- Three S3 buckets created (csv-raw-data , csv-processed-data and csv-final-data).
- IAM roles for Lambda and Glue with the necessary permissions.
- A QuickSight account linked to your processed data bucket.
With the foundational setup in place, you’re ready to move to the next section where we’ll handle data ingestion and preprocessing.

1.3 Data Ingestion and Preprocessing
Steps to be Performed
Create a Lambda Function
Write the Lambda Function Code
Setup S3 Event Trigger for Lambda
Test the Data Ingestion and
Preprocessing
#1 Create a Lambda Function
Now that we have the foundational setup, it’s time to automate the ingestion and preprocessing of CSV files. In this step, we’ll deploy a Lambda function that triggers automatically when a file is uploaded to the raw data S3 bucket
The function will clean and transform the data before saving it back to the processed data bucket. AWS Lambda allows us to execute code in response to events without managing servers.
Navigate to the AWS Lambda Console and click Create Function.
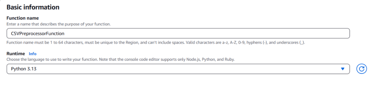
Choose Author from scratch and fill in the following:
- Function Name: CSVPreprocessorFunction
- Runtime: Select Python 3.13
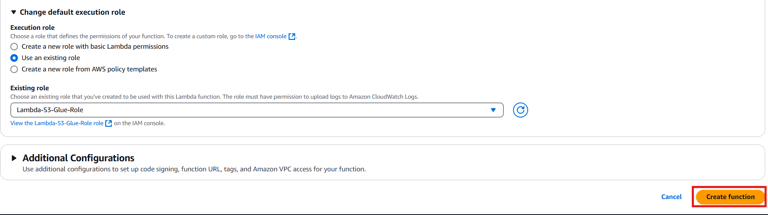
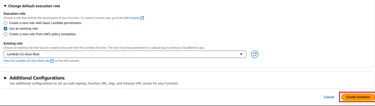
- Role: Choose Use an existing role and select the Lambda-S3-Glue-Role created earlier.
Click Create Function.
#2 Write the Lambda Function Code
Let’s write a basic preprocessing Lambda function to clean and filter CSV files
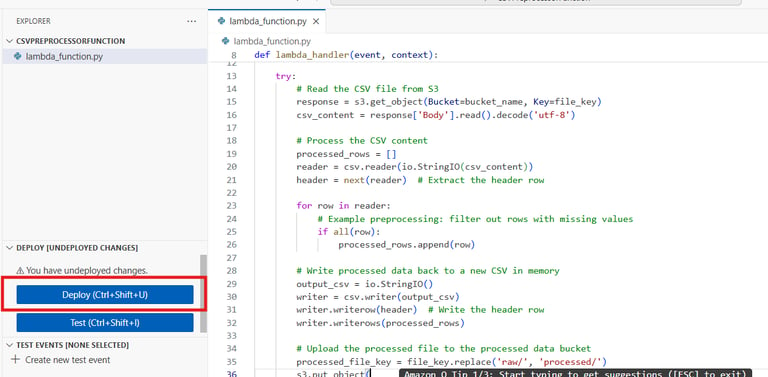
Scroll down to the Code section and replace the default code with the following:
💡 Make sure to change the Bucket name <YOUR_PROCESSED_BUCKET_NAME> to your actual processed data bucket name.
This AWS Lambda function is designed to automatically process CSV files uploaded to an S3 bucket. Here’s how it works in simple terms:
Triggered by S3 Upload – Whenever a file is uploaded to a specific S3 bucket (csv-raw-data), this function runs automatically.
Reads the File – It fetches the CSV file from S3 and reads its content.
Cleans the Data – The function removes rows that contain missing values, keeping only complete rows.
Creates a New CSV – It writes the cleaned data into a new CSV file in memory.
Uploads the Processed File – Finally, the function saves the cleaned file into a different S3 bucket (csv-processed-data).
Click Deploy to save the code.
💡 You can enhance this function based on your specific data transformation requirements
#3 Setup S3 Event Trigger for Lambda
Now that our Lambda function is setup, we need to configure the raw data S3 bucket to automatically trigger the Lambda function whenever a new file is uploaded in the bucket.
Go to the S3 Console and select your csv-raw-data bucket.
Navigate to the Properties tab and scroll down to Event notifications.
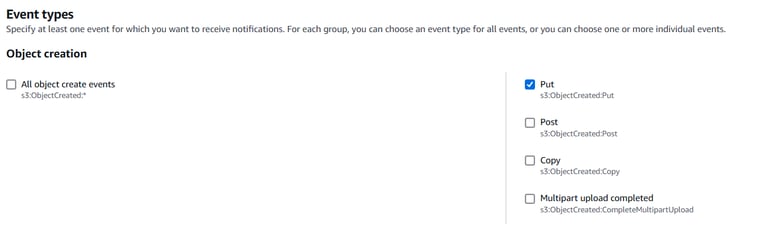
Click Create event notification and configure the following:
- Name: CSVUploadTrigger
- Event types: Select PUT (for new file uploads).
- Prefix: raw/ (All raw files are uploaded to this folder).
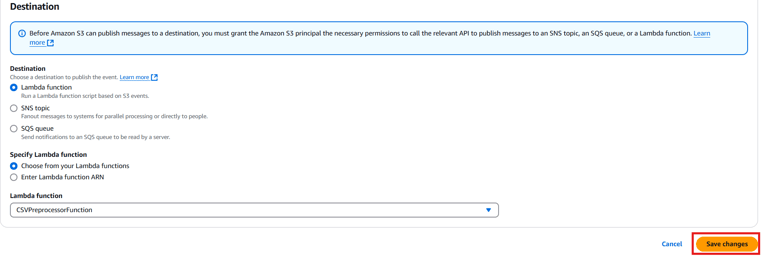
- Destination: Choose Lambda Function and select CSVPreprocessorFunction.
Click Save changes.
#4 Test the Data Ingestion and Preprocessing
Now lets test if the Lambda function is getting triggered when we upload a file in the raw data bucket and if it is getting preprocessed and stored in the processed bucket. To do this—
Upload a Sample CSV File:
Go to the S3 Console and navigate to your csv-raw-data bucket.
Create a folder named raw and upload a sample CSV file (weather-data.csv) to this folder.
You can download the weather-data.csv from here: LINK





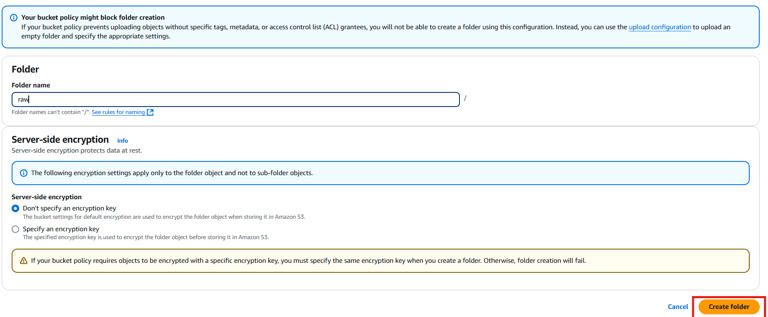
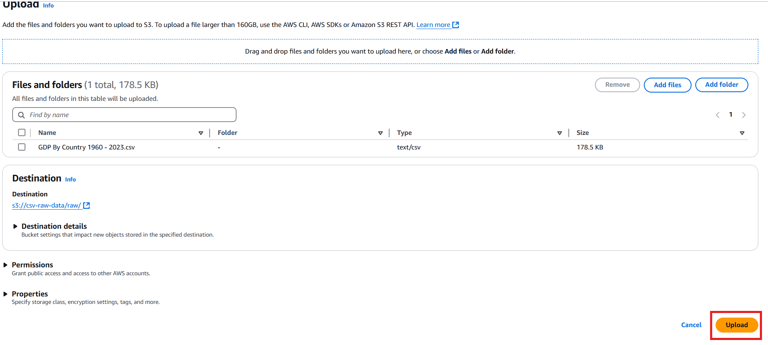
Check Processed Data:
Now since you added a new csv, this will trigger the Lambda function and store the processed CSV in the processed bucket. Navigate to your csv-processed-data bucket and verify that the processed CSV file is present in the correct folder.
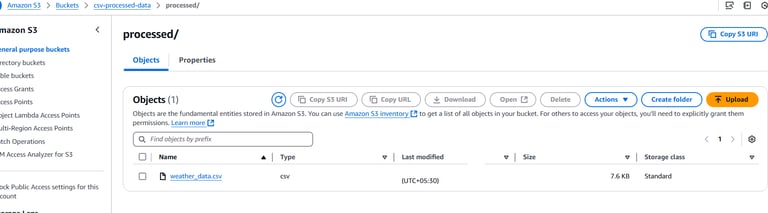
Final Check
Lambda function deployed and configured.
S3 event trigger set up and tested.
Processed CSV file verified in the processed bucket.
With data ingestion and preprocessing automated, you’re all set for the next section where we’ll learn about data transformation using AWS Glue!
1.4 Data Transformation with AWS Glue
Steps to be Performed
Setup an AWS Glue Data Catalog
Create a Crawler to Discover Data Schema
Create and Configure an AWS Glue Job using Visual ETL
Verify and Prepare Transformed Data for Visualization
#1 Setup an AWS Glue Data Catalog
Now that we’ve automated the data ingestion and preprocessing steps, it’s time to perform more advanced transformations using AWS Glue. AWS Glue is a fully managed ETL (Extract, Transform, Load) service that helps transform and move data between different storage layers.
In this section, we’ll set up a Glue job, define a data catalog, and execute transformations on the preprocessed CSV files stored in S3.
💡 What is AWS Glue? AWS Glue is a fully managed ETL (Extract, Transform, Load) service that helps automate data preparation and transformation.
💡 What is AWS Glue Data Catalog? AWS Glue Data Catalog is a centralized metadata repository that stores information about datasets, making them easily searchable and accessible for analytics.
💡 How is preprocessing through Lambda and Glue ETL different? Lambda is ideal for lightweight, real-time preprocessing of small files, while Glue ETL is better suited for large-scale, complex transformations on big data with built-in schema discovery and job orchestration. In this hands-on, we are trying to learn to use both ways.
Lets start with creating Glue Data Catalog—
Navigate to the AWS Glue Console.
• Click Data Catalogs → Databases → Add Database.
Provide the following details:
Database Name: csv_data_pipeline_catalog
Click Create.
📚 The database serves as a logical container to organize your tables and metadata.
#2 Create a Crawler to Discover Data Schema
A crawler automatically scans the data and creates metadata tables.
Go to Crawlers and click Add Crawler.
Fill in the following details:
Name: ProcessedCSVDataCrawler
Data Source: Choose S3 and provide the location of the csv-processed-data bucket.
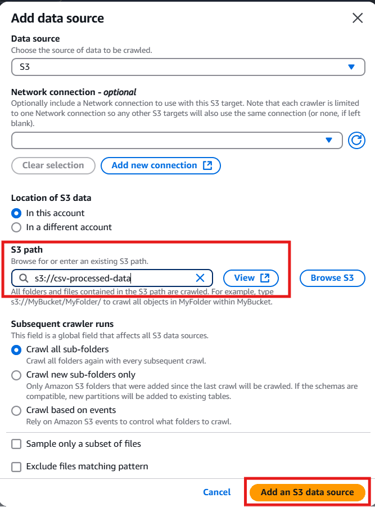
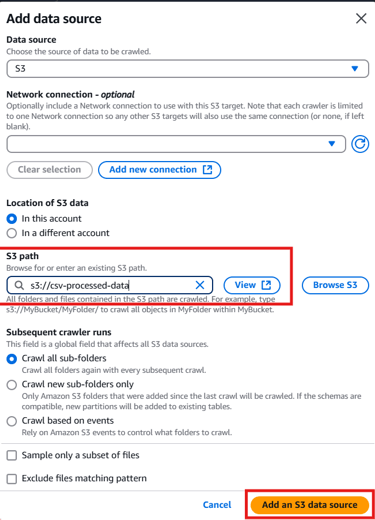
Click Next and configure:
IAM Role: Choose Glue-Service-Role Click Next.
Database: Select the csv_data_pipeline_catalog created earlier.
Schedule: Select Run on demand. Click Next.
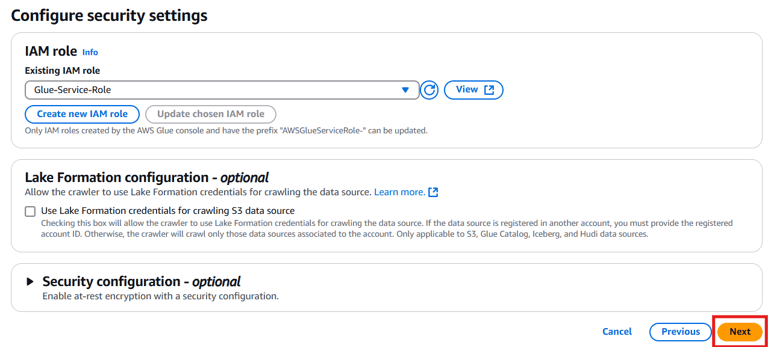
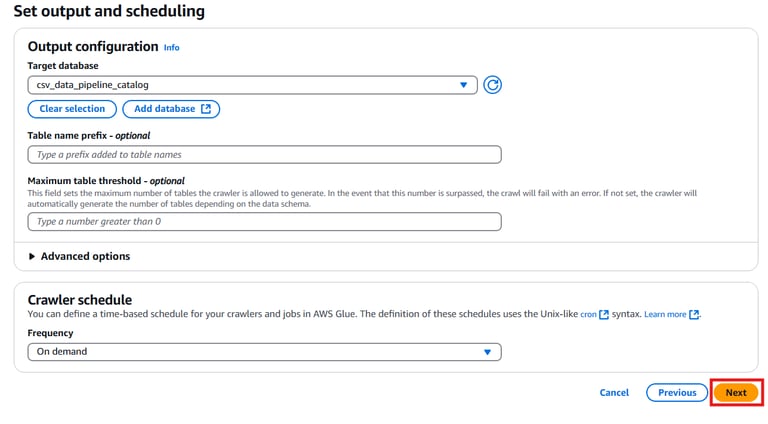
Click Create Crawler
Select the created Crawler and click on Run.
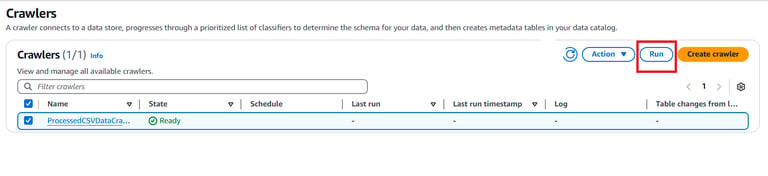
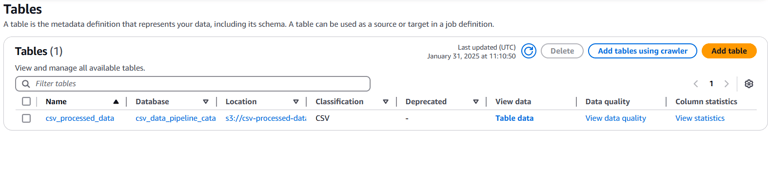
#3 Create and Configure an AWS Glue Job Using Visual ETL
Now lets proceed with creating the AWS Glue Job ETL pipeline using Visual ETL. To do this—
Access AWS Glue Studio:
Navigate to the AWS Glue Console, then click AWS Glue Studio from the left menu.
Create a New Job:
Click Jobs → Create ETLJob.
Select Visual ETL.
Define the Source:
In the visual canvas, click on the add button and go to Data Source.
Choose the AWS Glue Data Catalog. Under the database, choose the created csv_data_pipeline_catalog database.
Under the table, choose the csv_processed_data table created by the Crawler job.
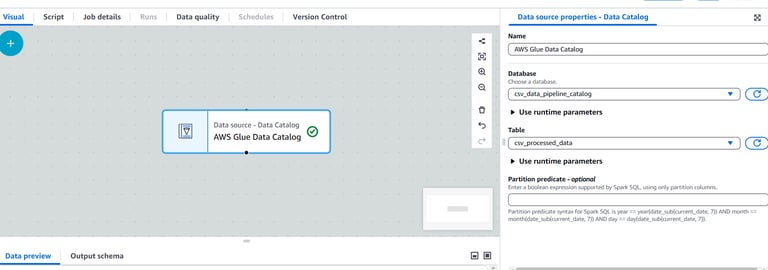
Add Transformations:
Click the + button after the source block and choose Change Schema for basic transformations.
Here I am going to drop the icon column so I will choose the checkbox for icon column.
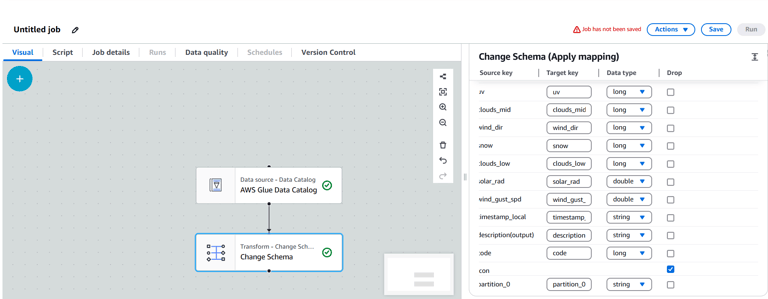
Define the Target:
Click the + button after the transformation and select Data Target.
Choose S3 as the target.
Enter the S3 path where the transformed CSV file should be stored (e.g., s3://csv-final-data/).
Format: Select CSV as the output format.
Compression: Choose GZIP as the compression type.
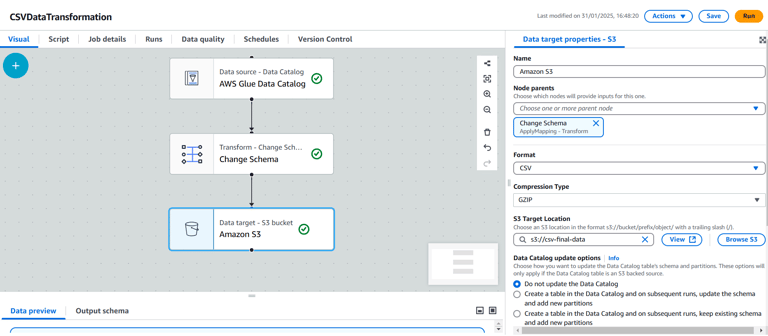
Configure Job Properties:
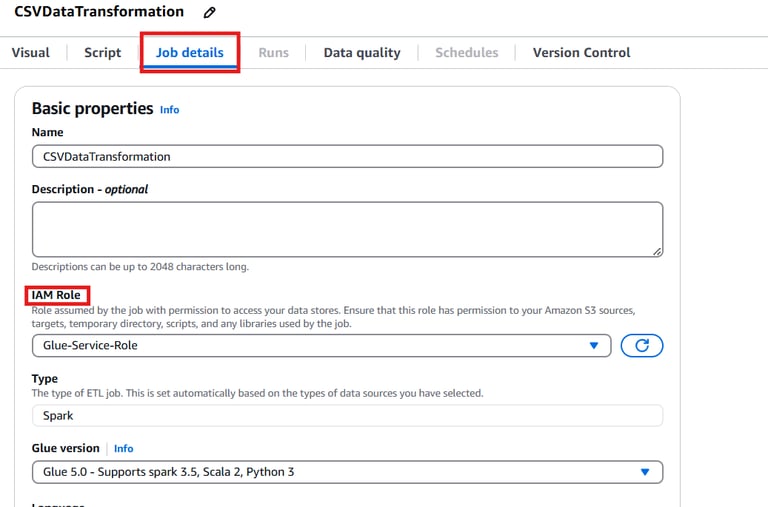
Click the Job Details tab on the right panel and provide the following details:
Name: CSVDataTransformation
IAM Role: Select an existing Glue role with access to S3 or create a new one.
Leave other advanced settings as default.
Save and Run the Job:
Click Save and then Run.
Monitor the job status in the Runs tab. It may take a few minutes to complete.
#4 Verify and Prepare Transformed Data for Visualization
After the Glue pipeline execution, the transformed data will be stored as a ZIP file in the target S3 bucket. Since the file inside may not have an extension, follow these steps to convert it to a proper .csv format.
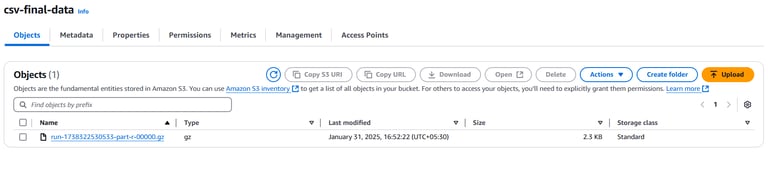
Navigate to the S3 Bucket:
Open the AWS S3 Console.
Locate and select the bucket where the transformed data is stored (e.g., csv-final-data).
Download the ZIP File
Click on the folder where the output is stored.
Select the compressed ZIP file and click Download.
Extract and Rename the File
On your computer, extract the contents of the ZIP file.
Locate the extracted file (it may not have an extension).
Rename the file to include a .csv extension at the end.
Re-upload the CSV to S3
Go back to the AWS S3 Console.
Click on Upload and select the renamed .csv file.
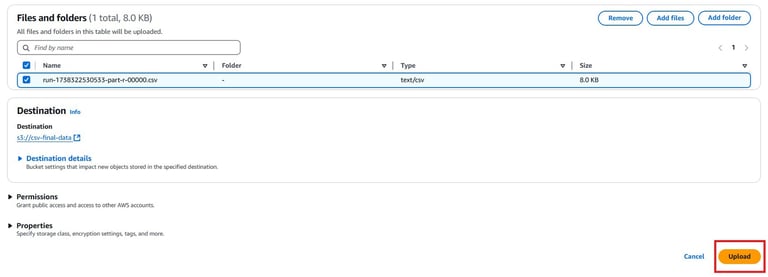
Click Upload.
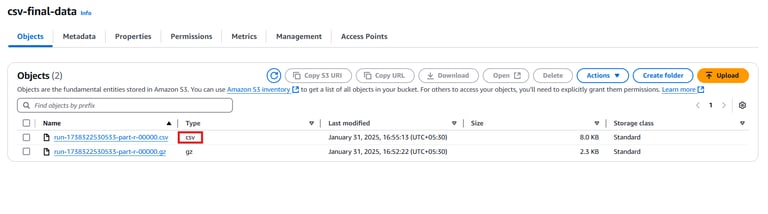
Verify the Upload
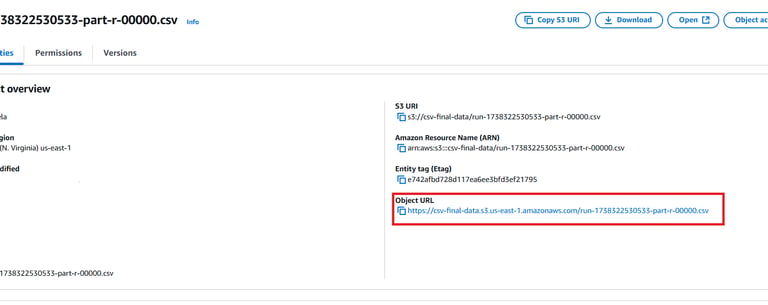
Confirm that the file now appears in the csv-final-data bucket with a .csv extension
It is now ready for visualization and analytics tasks. You can click on the csv file and copy the Object URL to use it for the further steps.
Final Check
Data Catalog created and configured.
Crawler set up and successfully discovered schema.
Glue job created and executed with data transformations.
Transformed data verified in S3.
Your data is now fully processed and ready for visualization in Amazon QuickSight! In the next section, we’ll set up QuickSight dashboards to visualize these insights.
Lesson Summary
Setup an AWS Glue Data Catalog: AWS Glue is a managed ETL service used for data preparation and transformation. The Glue Data Catalog is a centralized metadata repository for datasets. To create the catalog:
Navigate to the AWS Glue Console
Click Data Catalogs → Databases → Add Database
Provide Database Name: csv_data_pipeline_catalog
Click Create
Create a Crawler to Discover Data Schema
Go to Crawlers and click Add Crawler
Fill in details such as Name, Data Source (S3), IAM Role, Database, and Schedule
Click Create Crawler
Run the Crawler to generate metadata tables in the Glue Data Catalog
Create and Configure an AWS Glue Job Using Visual ETL:
Access AWS Glue Studio from the console
Create a new job using Visual ETL
Define Source, Add Transformations, and Define Target specifying the S3 path
Configure Job Properties including Name, IAM Role, and Save and Run the Job
Verify and Prepare Transformed Data for Visualization:
After Glue pipeline execution, locate the transformed data in the S3 bucket
Download the ZIP file, extract it, and rename the file with a .csv extension
Re-upload the CSV file to S3 and ensure it appears in the bucket with a .csv extension
The transformed data is now ready for visualization and analytics tasks using tools like Amazon QuickSight
1.5 Data Visualization with Amazon QuickSight
Steps to be Performed
Connect to the Data Source
Build a QuickSight Dashboard
Share and Publish the Dashboard
#1 Connect to the Data Source
We’ve successfully automated the ingestion and transformation of CSV data using S3, Lambda, and AWS Glue. The final step is to visualize this processed data using Amazon QuickSight, which will help turn processed data into actionable insights.
We need to connect QuickSight to the processed data stored in S3.
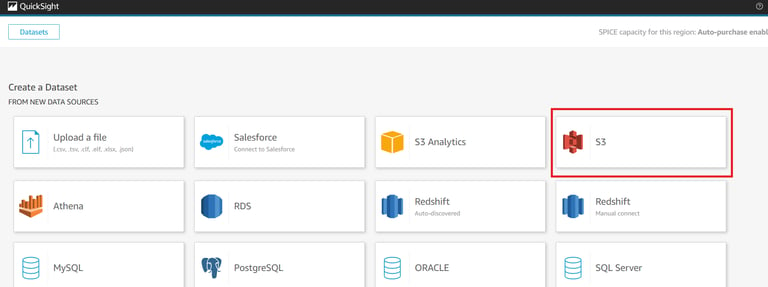
In the QuickSight console, go to the Datasets section and click New Dataset.
Select S3 as the data source.
Provide the following details:
Data Source Name: ProcessedCSV
Manifest File: Create a manifest file in your local machine with the following content and upload it from your local machine. Add the Object URL you copied earlier and replace it in the placeholder.
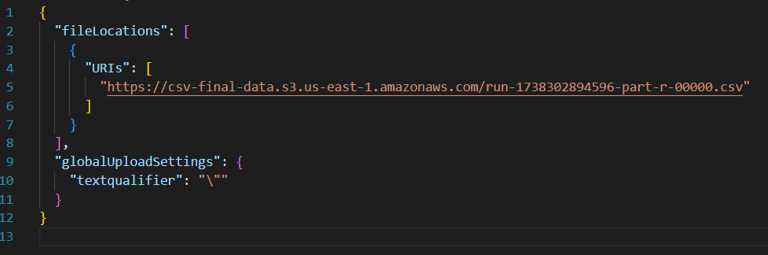
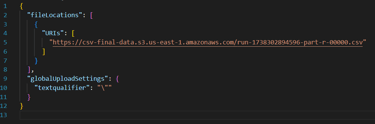
Upload the manifest file and click Connect.
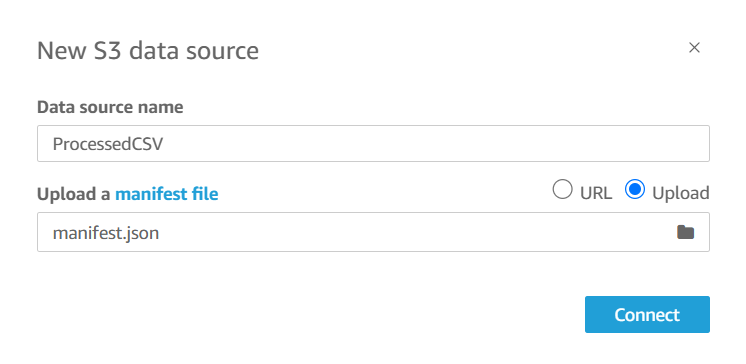
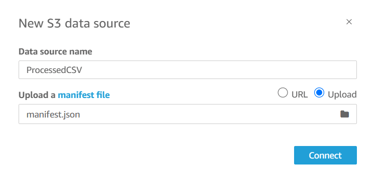
Click Visualize to load the data into QuickSight.
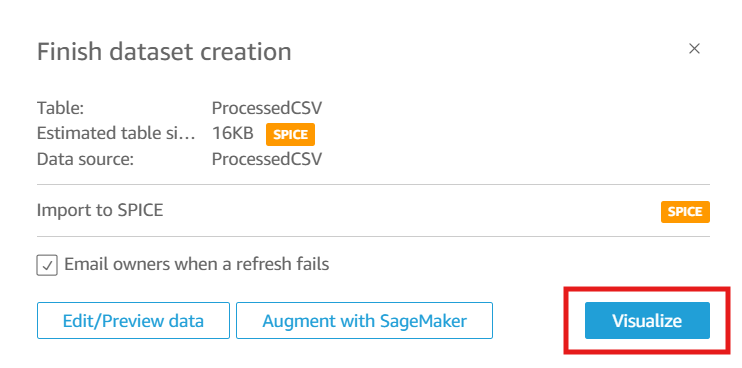
#2 Build a QuickSight Dashboard
Let’s create a dashboard to visualize the insights from the transformed CSV data.
Click Add to create a new analysis.
Select the ProcessedCSVData dataset.
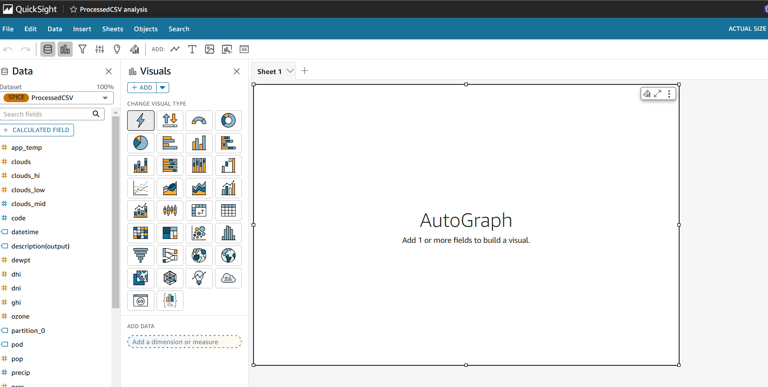
Build the following visualizations:
Bar Chart: Compare values from different columns.
Line Chart: Analyze trends over time.
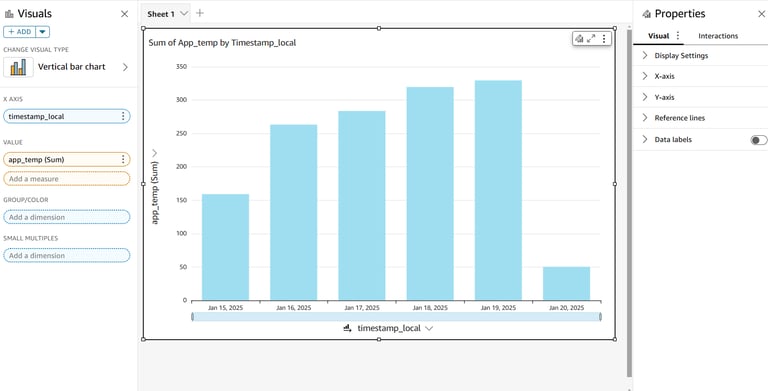
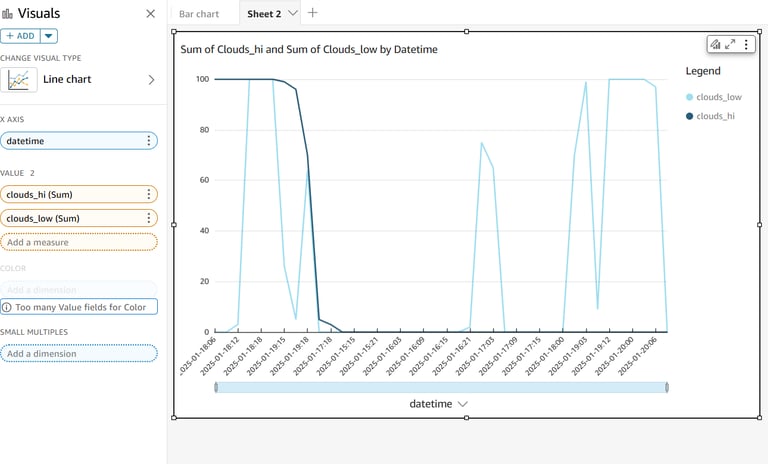
You can try out different charts by using the columns available in the dataset.
#3 Share and Publish the Dashboard
Select Publish Dashboard to make it accessible to other users.
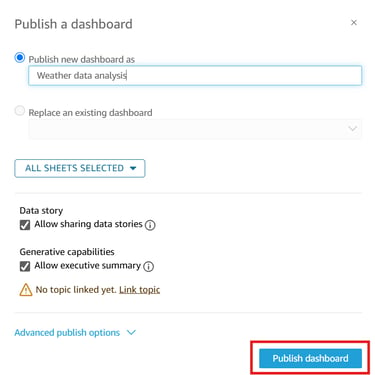
And here we go!!
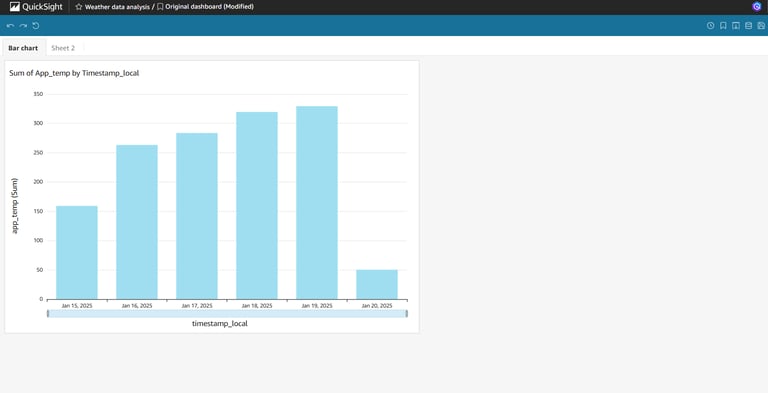
Final Check
QuickSight account set up and configured.
Data source connected and loaded into QuickSight.
Dashboard created with meaningful visualizations.
Pipeline tested with new data, ensuring dynamic updates.
This brings us to the completion of the data pipeline and Visualization for CSV files using S3, Lambda, Glue, and QuickSight.